機器學習(Machine Learning)
什麼是機器學習
機器能從「經驗或是資料」中學習,而後在某個「問題與任務」上「衡量標準」能有所提升,稱為機器學習
以一個人要準備考試為例
經驗或是資料(訓練資料):參考書、課本
問題與任務:考試
衡量標準:分數
機器學習類型
常見的有以下幾種:
- 監督式學習SL (Supervised learning)
- 非監督式學習UL (Unsupervised learning)
- 增強學習(強化學習)RL (Reinforcement learning)
監督式學習SL
我們能提供標準答案時使用
給予「資料」與「標籤」訓練機器
希望在「預測」時,輸入「資料」,可以輸出正確的「標籤」
常見的類型有以下幾種:
回歸問題(Regression Problem)
坪數(x)與房價(y),希望找到一個函數,找到x與y的關係
分類問題(Classification Problem)
給動物圖片及標準答案,判斷動物
結構化學習(Structured Learning)
輸入需求,輸出一篇文章或一個圖片
非監督式學習UL
我們不能提供標準答案時使用
給予「資料」,但沒有標準答案(標籤)
希望找到隱含的結構,也就是資料間隱藏的關係
舉例:
分群:在社交軟體中,有一群人,機器將興趣、年齡、職業等相近的人分群,分為多個群體。這時並沒有標準答案。
增強學習(強化學習)RL
訓練資料:來自於一系列與環境互動(observation)的行動(action)與獎勵回饋(reward)
目標:學習如何「選擇動作」以得到「最大的獎勵」
舉例:
玩小恐龍:看到障礙物跳起來的話給獎勵,沒看到障礙物時不跳的話給獎勵,最後恐龍就會越來越強。
玩賽車遊戲:當有障礙物時,躲避障礙物就給予獎勵,沒障礙物時,直行就給獎勵。
機器學習的流程
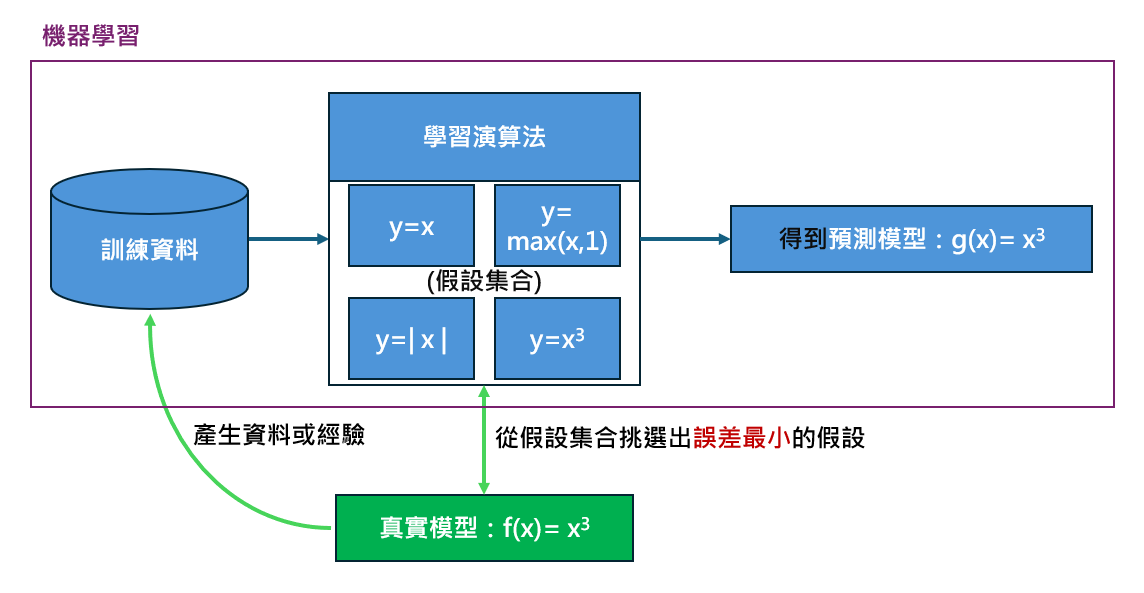
訓練資料
影像、語言、文章等
該注意避免:
噪音(Noise):題目被潑到墨汁(像小明一樣)
偏誤(Bias):要考英文讀到國文
獨立性:只給相同圖片,相同題目,只會訓練一次
學習演算法
挑選假設集合的演算法,如:
決策樹、支持向量機
假設集合 Hypothesis set
如:
線性模型
深度模型
真實模型
真實世界的樣子,通常是無法得知的。
線性模型的特徵轉換
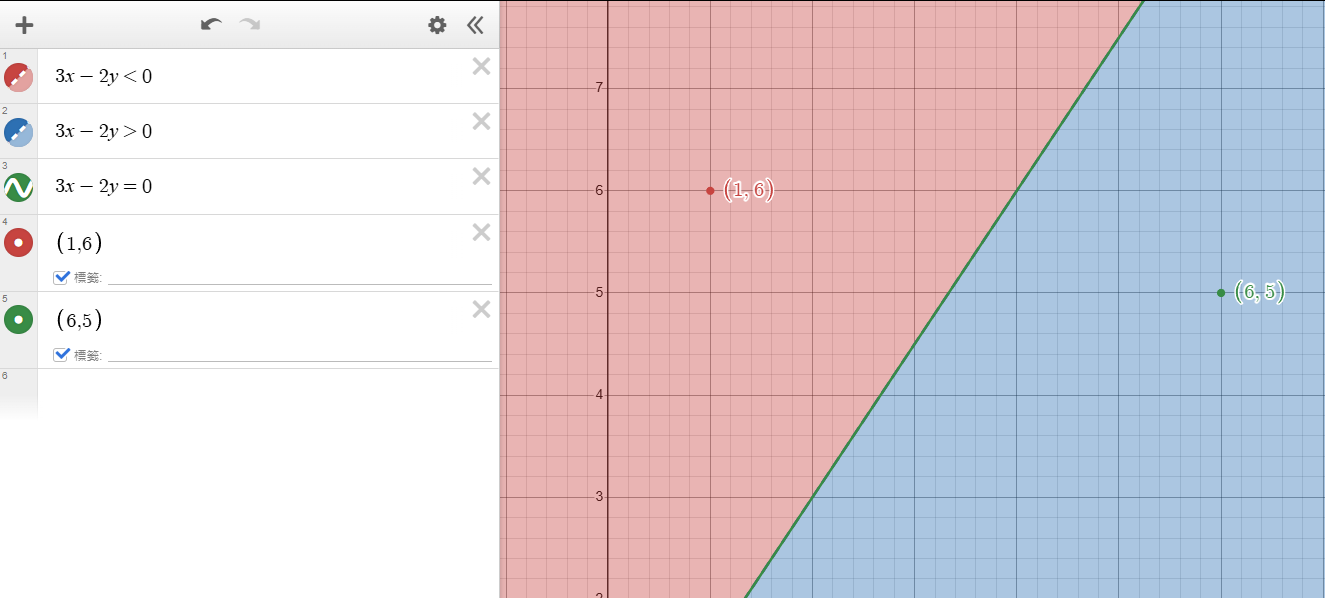
線性模型是利用一條線來分類的方式,如圖,我們可以用一條線 \(3x-2y=0\) 分割綠點和紅點。
在之後我們要判斷點是綠色或紅色時,只要看他在線的左邊還是右邊(是否大於0)就好。
而線性模型就是為了找出那條線。
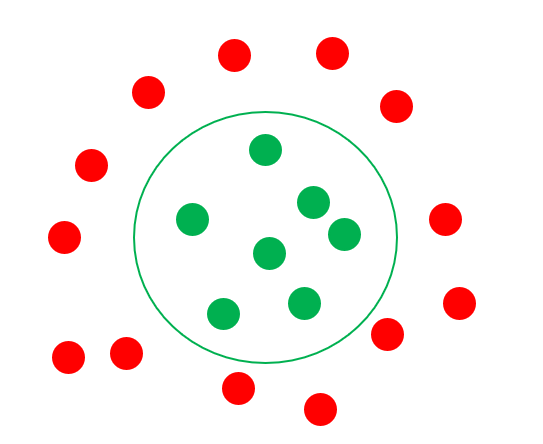
但是我們得到的資料往往不是分成左右兩邊,有可能像是下圖的分布,需要畫一個圓來分割,這將會很麻煩。
所以我們在得到資料之後先進行特徵轉換(\(\phi\)),再尋找可以分割的直線。
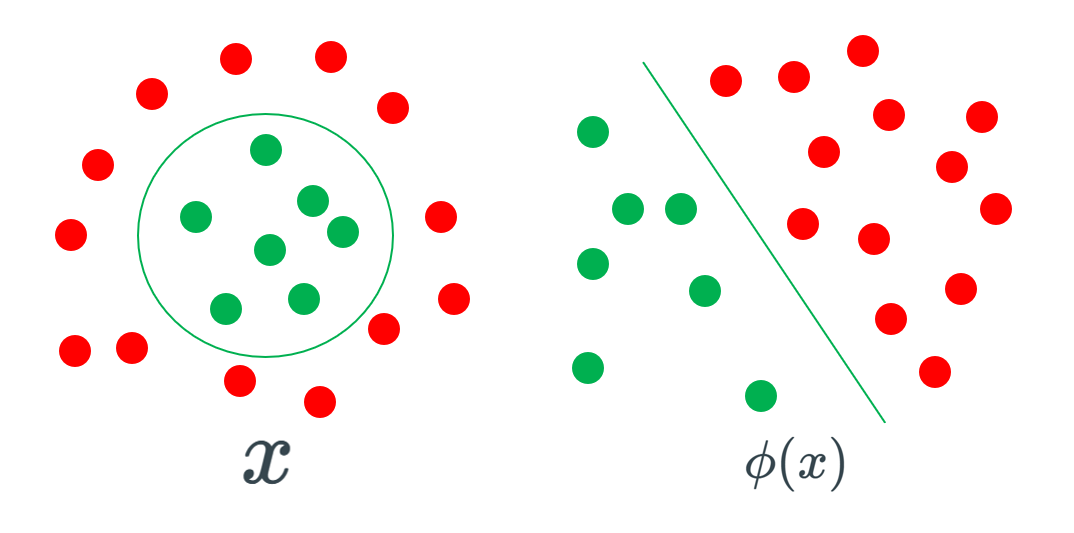
最後得到以下流程
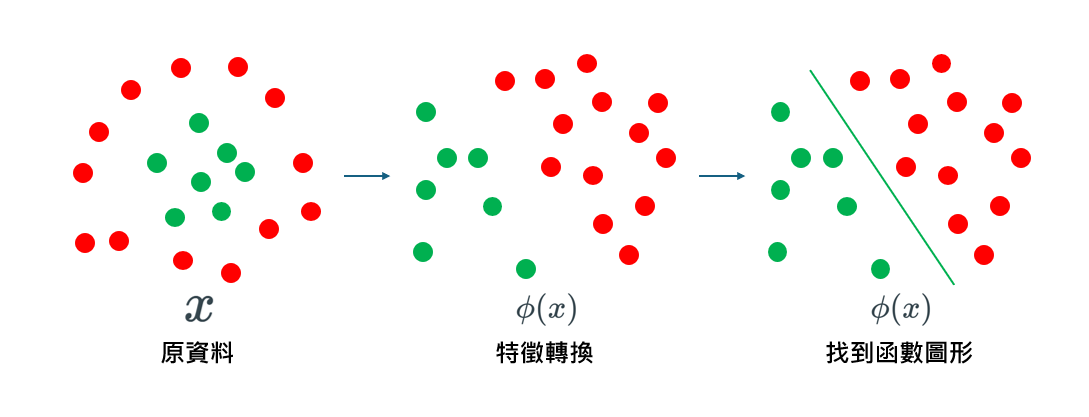
特徵轉換 Feature Transformation
把非線性的問題線性化,以符號\(\phi\)表示
線性模型
我們在決定假設集合時最常用的集合是線性函數,如下,有可能是一維,也可是二維,一般都是多維。
\[ f(x) = w_1x_1 + w_2x_2 + \cdots + w_nx_n = w^T x \]
以二維空間為例:
\[ f(x) = w_1x_1 + w_2x_2 = w^T x \]
\[
w^T =
\begin{bmatrix}
w_1 \\
w_2
\end{bmatrix}
\]
\[
x = \begin{bmatrix} x_1 & x_2 \end{bmatrix}
\]
若以空間表示,我們就可以有無限多個點,這就是假設集合,以下只標註其中一個點,但實際上有無限多個點。
不了解線性空間的話可以看這
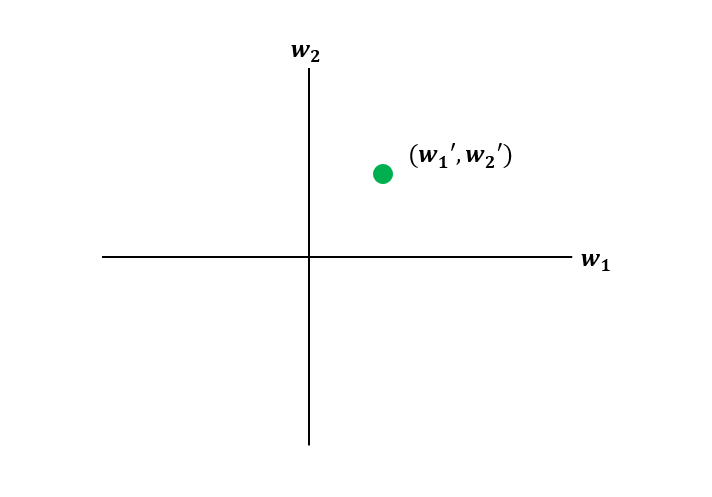
最後我們就要使用學習演算法挑選出最好的\(w^T\)組合。
我們舉個例子:
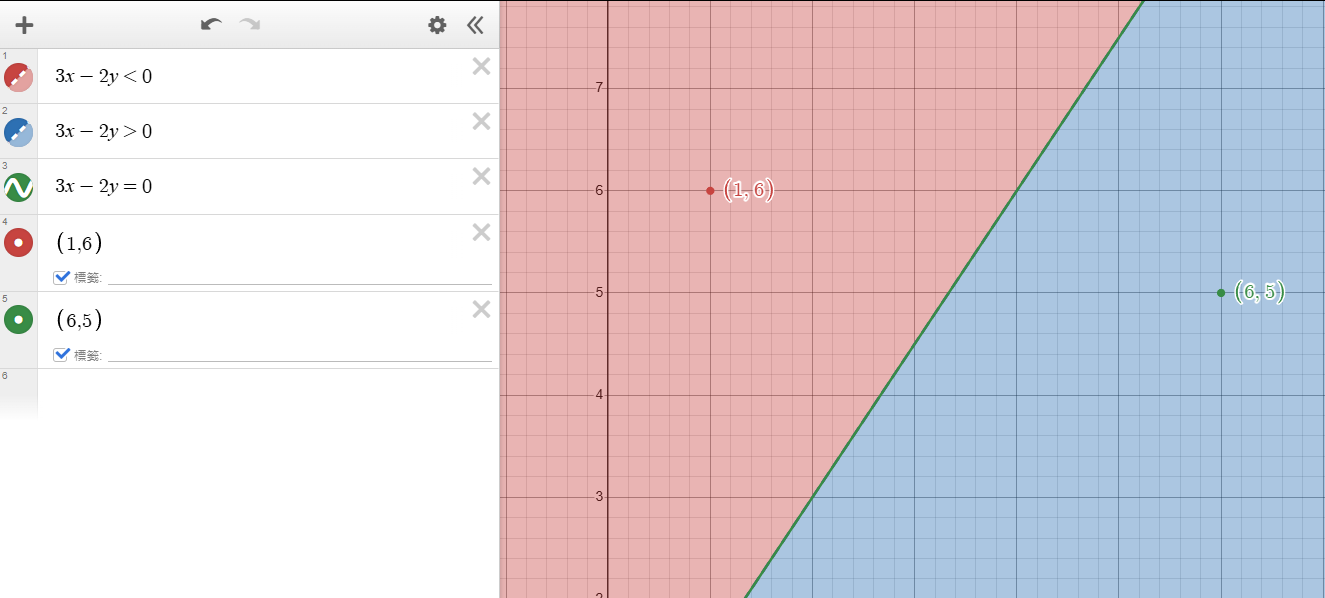
就像這裡選擇了\(w=(3,-2)\)
\[
w^T =
\begin{bmatrix}
3 \\
-2
\end{bmatrix}
\]
若輸入的 \(x =(6,5)\)
\[
x = \begin{bmatrix} x_1 & x_2 \end{bmatrix}
\]
進行計算:
\[
w^T = \begin{bmatrix} 3 \\ -2 \end{bmatrix}, \quad
x = \begin{bmatrix} x_1 & x_2 \end{bmatrix}
\]
\[
w^T \cdot x = \begin{bmatrix} 3 \\ -2 \end{bmatrix}
\cdot
\begin{bmatrix} 6 & 5 \end{bmatrix}
= 3 \cdot 6 + (-2) \cdot 5 = 18 - 10 = 8
\]
\(8>0\),所以在線的右側。
訓練遇到的問題
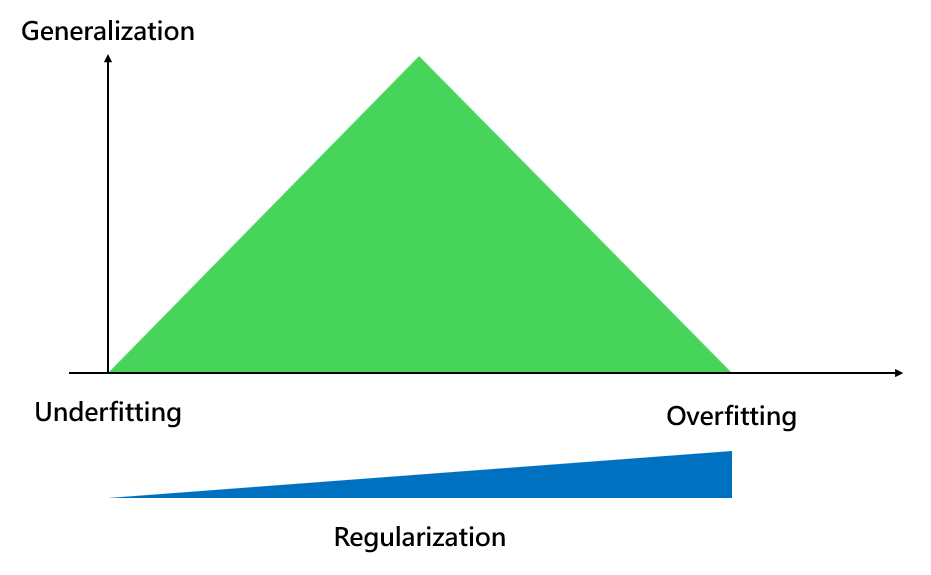
Generalization(泛化)
機器在訓練完成之後,在真實世界的實用性。
Overfitting(過擬合)
簡單來說是學習過度
因為模型自由度太高,模型太複雜。
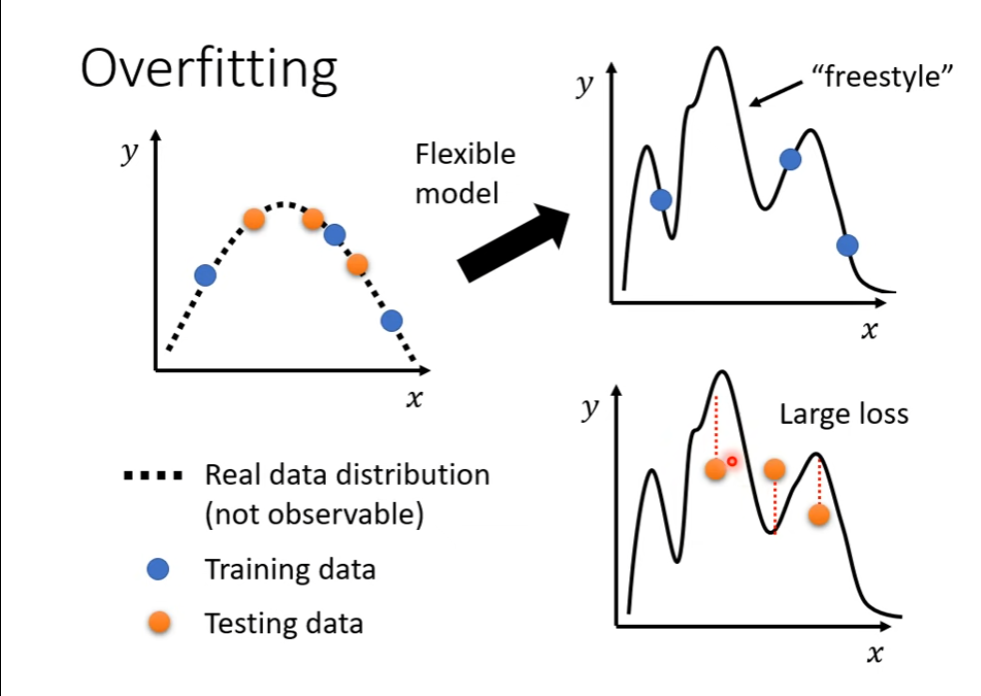
解決方法:
增加訓練資料
資料增強(data augmentation)
幾何轉換(Geometric Transformations)
-
旋轉(Rotation):隨機旋轉一定角度。
-
平移(Translation):隨機在水平或垂直方向平移。
-
縮放(Scaling / Zooming):放大或縮小影像。
-
翻轉(Flipping):水平或垂直翻轉。
-
裁切(Cropping):隨機剪取部分影像。
-
仿射變換(Affine / Perspective Transform):改變影像透視效果。
顏色與亮度調整(Color & Intensity Adjustments)
-
亮度調整(Brightness)
-
對比度調整(Contrast)
-
飽和度(Saturation)
-
色相偏移(Hue shift)
-
高斯雜訊(Gaussian Noise)
-
模糊(Blur)或銳化(Sharpen)
組合與高階方法
-
Cutout / Random Erasing:隨機遮住影像區域。
-
Mixup:線性混合兩張圖片與標籤。
-
CutMix:剪下部分影像貼到另一張圖上。
-
Mosaic / Copy-Paste:將多張圖片拼接成一張。
限制模型
限制減少維度之類的
Dropout
這時就需要正規化限制模型的學習
過擬合可以理解為你在準備考試時只死記硬背過去的試題,而不是理解考試主題的核心概念。結果,你在練習題上表現很好,但遇到新題時卻無從下手。
Underfitting(欠擬合)
簡單來說是欠缺學習
模型太簡單或是訓練不足,導致即使在訓練的資料中表現也不好。
過度正規化也會造成Underfitting(欠擬合)
Regularization(正規化)
限制模型的複雜程度,防止Ooverfitting